
2000年代半ばに始まった第三次AIブームはとどまるところを知らず、OpenAIがリリースしたChatGPTで一般層により浸透し、すっかりおなじみの存在となったAI。性能に差こそあれ、今やわたしたち人間の日常生活にさまざまな形で関わっています。まるで人間と話していると錯覚してしまうようなチャットボット、音声指示でさまざまなタスクをこなすスマートスピーカー、ファミレスなどで活躍している配送ロボットなどが典型例であると言えるかもしれません。また、判断や審査の分野でも、人間に代わってAIが間接的に関わっています。顔認識や、画像診断システムなどです。もうすでに切っても切れない関係にあるAIですが、文章や画像の生成AIの登場で、企業だけでなく個人でもAIを使うことができるようになりました。
AIは素晴らしいツールではありますが、完璧なツールではありません。とくに文章生成AIでは、「知りません」や「わかりません」といった選択肢を取らずに、回答者になりきってつらつらと知ったかぶりをした回答を出力したり、まったくのでたらめをさも本当の情報かのようにして出力したりと、なかなかに不正確な回答を自然な文章で出してくるという特徴も知られています。
そのため、AIを活用する際にはリスクが存在していることを認識する必要があります。たとえば人々のプライバシーに関わる情報を扱う際、半分真実・半分嘘の情報や誤った予測による結果をそのまま使うことは避けなければいけません。また、AIは人間のように感情や倫理観を持ち合わせていないため、公平で偏見のない判断をすることは期待できません。
したがって、人間とAIの関係性はすでに、「AIを実務で活用するにはどうすれば良いのか」というフェーズから「リスクをコントロールしてAIに悪いことをさせないように実務で活用するにはどうすればよいのか」ということを考えるフェーズに到達しています。
この記事では、「テキスト生成AIの安心運用」にフォーカスして、リスクをしっかり認識してAIを安心して運用するヒントについて考えてみます。
海外の最新コールセンターシステムやデジタル・コミュニケーションツールを、17年間にわたり日本市場へローカライズしてきた株式会社コミュニケーション・ビジネス・アヴェニューが解説します。

そもそも生成AIってどういう仕組み?
まずは、生成AIについて、一体どうしてあんなにスラスラと質問に答えられるのか、その仕組みの部分をおさらいしておきます。
ChatGPTは、人工知能技術の一種で、OpenAIが開発したチャットボットです。人々との対話によって情報を共有し、質問に回答したり、会話を進めたりすることができます。GPTは「Generative Pre-trained Transformer」の略であり、大量のデータを学習することで言語理解を向上させます。2022年11月時点では、ChatGPTはGPT-3.5のバージョンに基づいており、幅広いトピックに関して理解と応答能力を持っています。
上の文章は、ChatGPTに「ChatGPTとは何か、専門用語を使わずに、200文字程度で解説してください。次のキーワードを含んでください。「OpenAI」「2022年11月」」と質問した結果、生成された文章です。「2022年11月」というキーワードを入れたのは、OpenAIがChatGPTをリリースした時期を入れてくれるかもという期待によるものでしたが、結果は少し違っていました。が、「ああ、そうなんだ」と普通に受け入れられるくらいに自然です。
AIの急速普及の背後にあるのは、深層学習(ディープラーニング)という技術で、コンピューターが自ら学習する機械学習の一種です。画像認識の分野で大きく注目を浴びたディープラーニングですが、テキストを扱う自然言語処理の分野でもイノベーションを巻き起こします。自然言語処理とは、わたしたちが使っている言語をコンピューターに処理させる技術のことで、文章を生成する際には、文章の並び方に確率を割り当てることを特徴とする「言語モデル」が使用されます。
言語モデルを使用すると、たとえば「カラスの色は」という文章のトークンがあったとして、その次に高確率で当てはまりやすい「黒です」という単語を使用して文章が出力されます。ここで、正しい文章としての出力精度を向上させるのに、ある特定の言葉の次に当てはまりやすい言葉の特徴を認識する必要がありますが、そのデータの特徴を学習するのに用いられたのがこのディープラーニングという手法でした。
ChatGPTのベースとなっているAIは、Generative Pre-trained Transformer(GPT)というものです。
Transformerという技術は、2017年にGoogleの研究チームが開発したアルゴリズム(Attention is All you Needという論文に基づく)が元になっています。このアルゴリズムは、「学習するデータのどの特徴に注意(Attention)を向けるか」を学習するのが目的です。Transformerがこれまでのモデルと決定的に異なる点は、「精度が高い」という点です。たとえば、「残業で遅くなってしまったから、早く」という文章に対して、次に来るのは「帰る」なのか「寝る」なのか「食べる」なのか、一番確率が高い単語を予測する必要があります。Transformerでは、文章の関連性を、単語データの特徴に注意を向けつつ学習することができるため、わかりやすく適切な文章を生成することができるのです。
ChatGPTのような生成AIが文章の続きを生成する際、どんな事が行われているかを簡潔に示すと以下のようなイメージとなります。
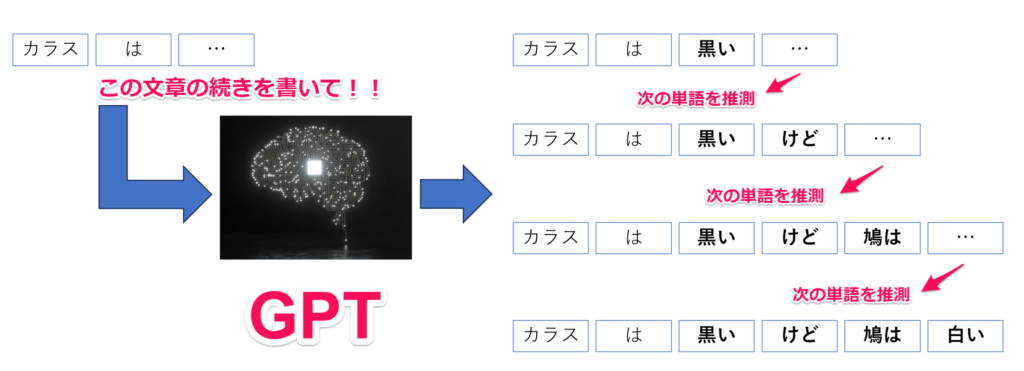
ChatGPTの学習のベースとなっているのは、膨大なインターネット上のテキストデータです。これらを元にした学習により、ChatGPTは与えられた文章の先を、高確率で使用される単語を予測して文章を出力し続けます。またより自然な文章にするために、人手で微調整とチューニングが行われてもいます。

生成AIのメリット・デメリット
そんな生成AIですが、活用に際してメリット・デメリットをまとめてみました。
メリットは…
- 時間の節約
- 定型業務の効率化
- SEO対策の強化
- アイデアの創出
メリットの特徴として、効率化が挙げられます。たとえば、メールや広告文、商品説明と言ったさまざまなタイプの文章を作成する場合、人間がゼロから作るとそれなりの時間がかかりますが、テキスト生成AIの手を借りることで、時間をかけることなく文章を取得できます。しかも、必要な情報を入力するだけで何例でも取得することができるので、時間の節約と業務の効率化につながります。
アイデアの創出も、メリットの一つです。ウェブ上の膨大な情報から幅広くさまざまな選択肢を提供できるテキスト生成AIは、人間では思いつかなかった、または発見するに至らなかった情報や案を生み出すことができます。そして、過去の大量の文章やニュース記事などから傾向・パターンを抽出することも得意なため、企業の商品活用や市場分析、競合他社の情報分析にも使用することができます。
デメリットは…
- 情報の不正確性
- 不安定な品質
- フェイクコンテンツの創出・拡散につながってしまう
- セキュリティ・倫理リスクが存在する
ウェブ上のテキスト情報を大量に学習するというその性質上、そもそも学習データに間違いが混入していた場合は、正確な文章を生成することはできません。つまり、出力される情報の正確性を担保するのは不可欠だということになります。たとえばSNS投稿やブログ記事といった、個人の意見に基づいたもの、または誤解が含まれがちなデータやコンテンツが含まれる可能性があります。出力されたものが本当に正しいのかどうかをしっかりと確認する必要があります。このデメリットから、生成AIを活用する上での懸念点が浮かび上がってきます。
生成AIに伴うリスク
Gartnerのアナリスト、Avivah Litan氏によれば、生成AIを活用する上で最大の懸念は信頼性とセキュリティに関連しているとしています。以下のリスクが含まれます。
ハルシネーション
「ハルシネーション」とは文字通りには「幻覚」を意味します。生成AIにおけるハルシネーションとは、事実とは異なる内容をもっともらしく出力されることを指しています。あたかも、人間が脳内で夢や幻を見てそれをそのまま現実と混同して語っているようなものです。

たとえばChatGPTで「日本に生息していた恐竜を教えて?」と質問したところ、上記の回答が返ってきました。いくらネット検索してもまったく情報が出てこない「恐竜」で、おそらく「もっともらしいウソ」だと思われます。ハルシネーションが厄介なのは、本当かどうかの見分け・判断がつきづらいというところです。Litan氏は、「学習データによってバイアスがかかった回答や的外れな回答が出力される可能性があり、生成AIの活用が進むにつれてそうした誤りを発見することが困難になる」と述べています。
ディープフェイク
「ディープフェイク」とは、AIを使って架空の写真や動画生み出す技術のことで、2010年代半ばくらいからこの技術による事例が現れ始めています。たとえば、ロシアの反政権運動家アレクセイ・ナワリヌイ氏の側近、レオニード・ボルコフ氏になりすました人物が、ラトビアなどバルト三国の政治家らとビデオ通話を行ったと、イギリスのガーディアンが2021年4月に報道しています。また、2022年3月には、ウクライナのゼレンスキー大統領になりすました人物が、ロシア軍への抵抗をやめるよう国民に呼びかけている動画が出回りました。社会に与える影響も大きく、深刻な被害や問題を引き起こす可能性があります。
データプライバシー
学習の目的でユーザーデータが保存されることが多い生成AIでは、個人情報などのデータプライバシーも大きな懸念点となっています。また企業での活用においては、従業員が気密性の高い独自データを生成AIに入力することで、機密情報の漏洩を引き起こす可能性について指摘されています。そうした情報が、悪意を持った第三者の手に渡るリスクについても無視できません。
著作権問題
著作権で保護されたデータも、生成AIの学習に使用されている可能性があるため、出力の一部が著作権や知的財産権に違反する可能性があります。したがって、情報ソースの参照や出力に際して透明性を確保する必要があり、現状はエンドユーザーが出力をしっかりとチェックする必要があります。
サイバーセキュリティ問題
生成AIは、プログラムコードの生成にも長けているため、悪意のあるコードを生成する目的で、サイバー犯罪者がこうしたツールを使用する可能性があります。しがたって、生成AIが悪用されると、深刻なサイバーセキュリティの懸念が発生します。
また、こうした問題は、倫理リスクとしても密接に絡み合っています。
たとえば、アマゾンの履歴書審査AIのケースは、AIのバイアス問題を象徴する例として広く知られています。アマゾンは自社の人材採用プロセスを効率化するために、応募者の履歴書をAIに解析させ、次の選考過程である人間による面接に進むべきかどうかをAIに判断させるという試みを実施しました。しかし、実際にAIを開発しテストした結果、女性の評価が不当に低くなるというバイアスが発見されました。報道によれば、アマゾンはこのAIの開発に2014年から取り組んでいたものの、2017年にはバイアス問題を解決できないとしてその利用を断念。数年にわたる取り組みが結果的に失敗に終わってしまいました。仮にこれが問題視されずに実際に運用されていたとしたら、後々訴訟問題などが発生していたかもしれず、ブランドの失墜によるさらなるダメージを被っていた可能性もあります。

生成AIを安心運用するためにできる4つのこと
こうしたリスクを考えると、生成AIを安心して活用するためには、倫理、偏見、透明性、プライバシーやコンプライアンスといったリスクをしっかりと見据えたリスクマネジメント、そしてガバナンスを確立する必要があります。信頼性の確保は最優先事項であり、顧客接点において生成AIを活用する場合はとくにそうです。お客さまへダイレクトに影響が出るからです。生成AIに固有のリスクを積極的に減らし、AIの運用に対して責任あるアプローチを促進する必要があります。
以下をベースに、生成AIの運用に関するガバナンスを検討できるかもしれません。
1. 信頼できる環境の構築
情報漏洩や機密データの流出などのリスクを最小限に抑えるため、技術的な対策を講じておくことが大切です。データ漏洩のリスクが考えられるアプリケーションレイヤーを、独自に開発したカスタムフロントエンドと置き換えることで、ChatGPTアプリケーションをそのまま直に使う必要がなくなるため、漏洩リスク対策となります。
またデータを隔離するサンドボックスも有効となります。いずれにしろ大切なのは、機密データをしっかりと自社管理できる体制を整えることです。信頼性の確保を視野においた設計で先手を打つ必要があります。
2. 従業員教育
ChatGPTを始めとする生成AIは大きく普及しています。それに伴い、従業員はそうしたツールを手軽に使うことで、いわばAI利用を独学で学んでいる状態です。ソーシャルメディアなどを通じて、誤った情報から学習する可能性も否定できません。簡単にAI関連のツールにアクセスできるということは、新たなサイバーセキュリティの脅威をも引き起こす可能性があるということです。
したがって、従業員の生成AIリテラシーに関する教育が非常に大きな意義を持つことになります。従業員は、自分たちが被る可能性のあるビジネスリスク、セキュリティリスク、そして生成AIのベストプラクティスや有効なユースケースなどについてのナレッジをしっかりと取得する必要があります。日進月歩の世の中だからこそ、必要な施策です。
3. 透明性・説明可能性の確保とプライバシーの保護
AIモデルの透明性および説明可能性の確保は、顧客のブランドに対する信頼性の維持と説明責任を果たすために不可欠な要素です。
たとえば、保険会社が顧客接点において生成AIを保険金請求額の予測のために活用していたとします。保険会社には、なぜその請求額となっているのか、その見積もり額に決定するに至る根拠を顧客に対して説明できなければなりません。でなければ、顧客は納得しませんし、「AIが自動的に算出しました」では信頼性は確保できないからです。
つまりデータ可視化や意思決定ツリーなど、説明可能性を確保できる技術を導入すること、しっかりとしたドキュメントを提供すること、生成AIに意思決定を委ねないシステムを構築すること、またコンテンツ作成に生成AIを活用する場合には、AIがコンテンツ活用に使用されたことを明示する仕組みを確立しておくことで、透明性の確保につながります。
またプライバシーの保護も抑えておくべき重要なポイントです。個人のプライバシーに関する機密情報をAIが誤って公開することのないように、また実際の個人データに類似した合成データを生成し公開しないようにするため、プライバシー保護に関する技術の導入を検討するのは最重要と言えます。データの匿名化、暗号化、差分プライバシーなどが含まれます。
4. 人間とのコラボ強化
生成AIは、確かに多くの選択肢を網羅的に捉えつつ優先順位をつけて絞り込んでいくところに強みを発揮します。だからといって、生成AIの活用にまつわるデメリットや実際に起きている事例などに鑑みるに、生成AIに意思決定を完全に委ねてしまうのは危険と言わざるを得ません。間違いやバイアスが含まれたデータで学習したことで、出力にそういったネガティブな要素が混入していた場合、しかもそれが非常に自然に表現されている場合、その出力結果により大衆扇動が起きかねません。
やはり、人間が意思決定ループに入っていることが必要です。人間の視点と判断を反映させることで、生成AIの品質と信頼性を高めることにつながります。生成AIは人間の能力を強化し、力を与えるツールとして活用されるべきであり、人間を置き換えるものではないことは、これまでに起きている事例や混乱を見れば理解できることです。
最後に
生成AIからは少し話が飛びますが、少し前に自動衝突防止機能と高速道路などで便利なオートクルーズコントロールが搭載された車を運転する機会がありました。自動衝突防止機能を試すのはあまりにも危険すぎるため、もちろんやめておきましたが、高速道路ではオートクルーズコントロールを試してみました。アクセルを踏む必要がなく、ドライバーの労力を軽減できる機能として非常に有用でしたし、車間距離も検知できるので安全性も確保されていると感じました。同時にメーカー側の説明を読むと、こうした機能はあくまで「運転サポート技術」と位置づけられており、完全自動運転でドライバーを置き代えるものではありません。ここに、AIと人間の関係性が反映されているようにも思えました。
生成AIは広く普及していますが、企業がこれを活用する際には倫理的なリスクが存在することは明らかです。したがって、企業は生成型AIの責任ある使用を優先するために、正確性、安全性、誠実さ、持続可能性を保証する必要があります。企業は倫理的な影響に留意し、リスクを軽減するために必要な対策を講じるべきでしょう。
