
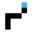


今回は、弊社が行っている顧客接点に関する開発の様子をお伝えします。
本記事で紹介するのは、自治体用のGPT開発の概要です。「自治体がすでに持っているFAQデータを、ChatGPTを活用してどのように市民に提供できるか」という点に取り組みます。
デモ開発の様子を弊社のエンジニアに取材しました。最後には、開発を通して見えてきたエンジニアの気づき、TIPS、課題などを紹介するのでご覧ください。
デモ開発を指揮したエンジニアの川村に話を聞いていきます。
ChatGPTをコールセンターシステム「Bright Pattern」に連携してみた - オムニチャネル・クラウド型コンタクトセンターシステムBright Pattern |
Azure OpenAIをコールセンターシステム「Bright Pattern」に連携してみた - オムニチャネル・クラウド型コンタクトセンターシステムBright Pattern |
①肩書を教えてください
グローバル事業部プロフェッショナルサービスマネージャーです。
お客さまの要望に応える開発・コンサルティング業務を行っております。
②今はどんな開発をしていますか
大規模イベントで使用するリアルタイム通訳アプリケーションの開発を行っています。12の言語に対応するイベント用通訳アプリです。
③GPTの開発は最近ありましたか
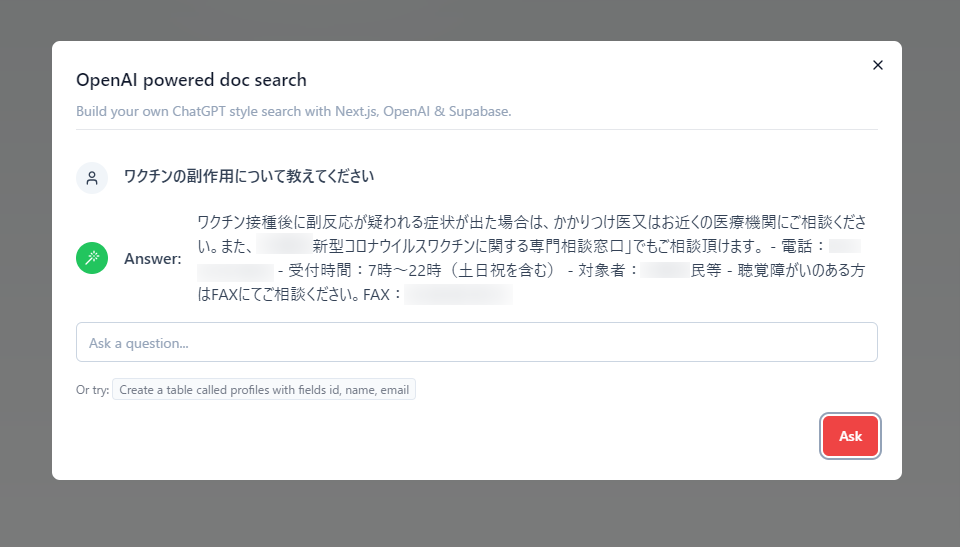
自治体用のChatGPTのデモ開発をしました。自治体から提供されたエクセル形式のFAQ情報をナレッジベースとして、ChatGPTが市民からの質問にチャット対応できるサイトを作りました。
④自治体用のChatGPTについて教えてください。どんなツールを使いましたか
以下の3つのツールです。
- Vercel
- DB(pgvector)
- OpenAI(モデル:gpt-3.5-turbo、text-embedding-ada-002)
サイトを簡易的に作る「Vercel」、FAQの文章をベクトル化し格納するためにadaと「ベクトルDB(pgvector)」、そして質問と類似するFAQを取得するためのadaと、類似するFAQを元に質問への回答を生成するためのGPTを使用しています。
⑤動作の全体図のようなものはありますか
以下の図を参考にしました。

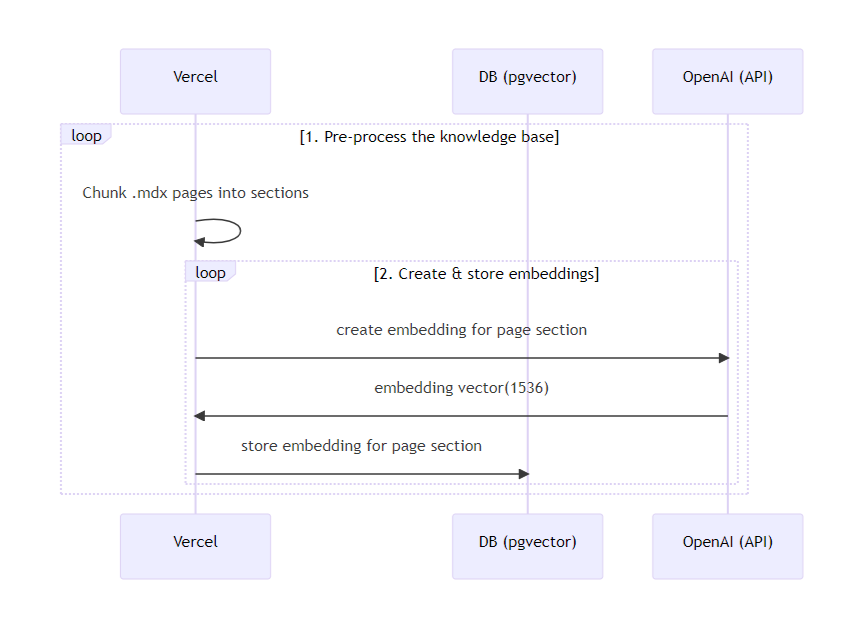

⑥設定の大まかな流れを教えてください
- OpenAIでAPI Keyを発行し、取得したAPI Keyをソースコードに貼り付ける
- FAQの文章に対してベクトル値を計算する
- 質問が生成される仕組みを実装する
全体の流れを解説します。
まず開発に必要なAPI Keyを準備します。
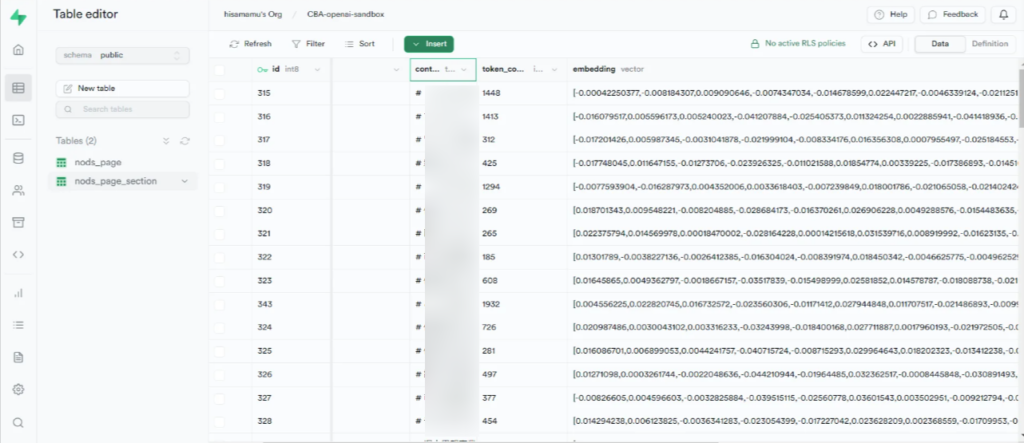
次に、エクセル形式のFAQのテキスト情報をプログラムで抽出し、OpenAI adaモデルのAPIでベクトル化します。単語や文章等の自然言語の構成要素をベクトル値(数値)に変換することで、文章同士の類似度を測定し、質問と類似したFAQを取得できるようになります。
その後、類似したFAQをもとに質問への回答を生成するようGPTに指示する流れです。
⑦設定の手順を教えてください
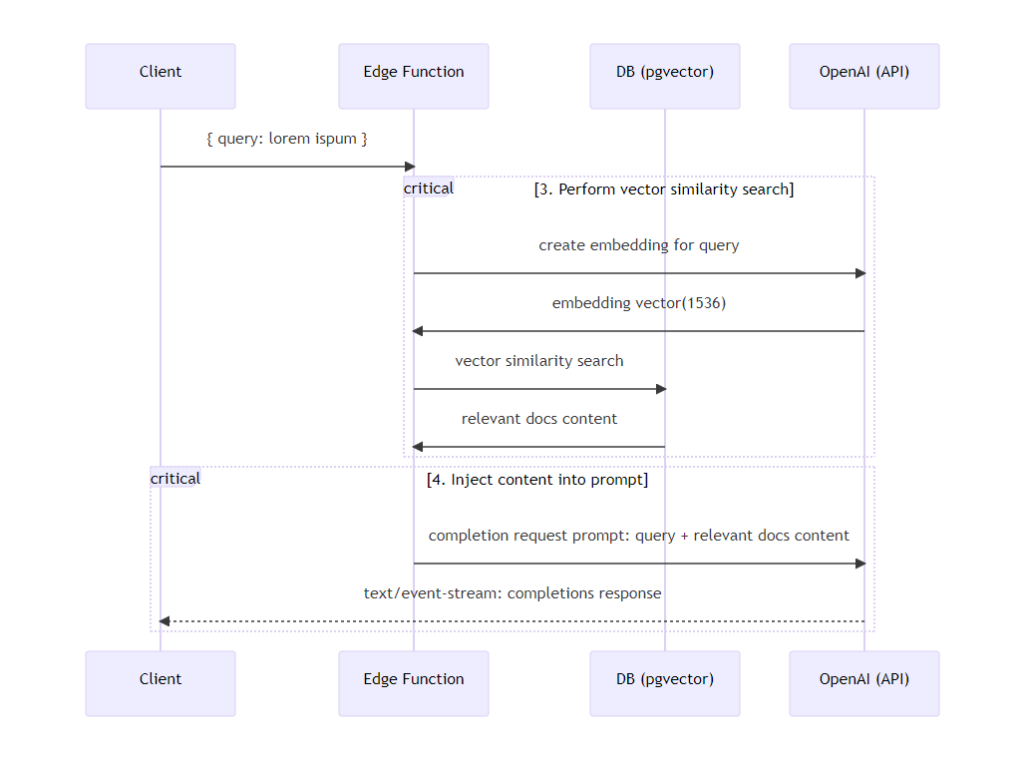
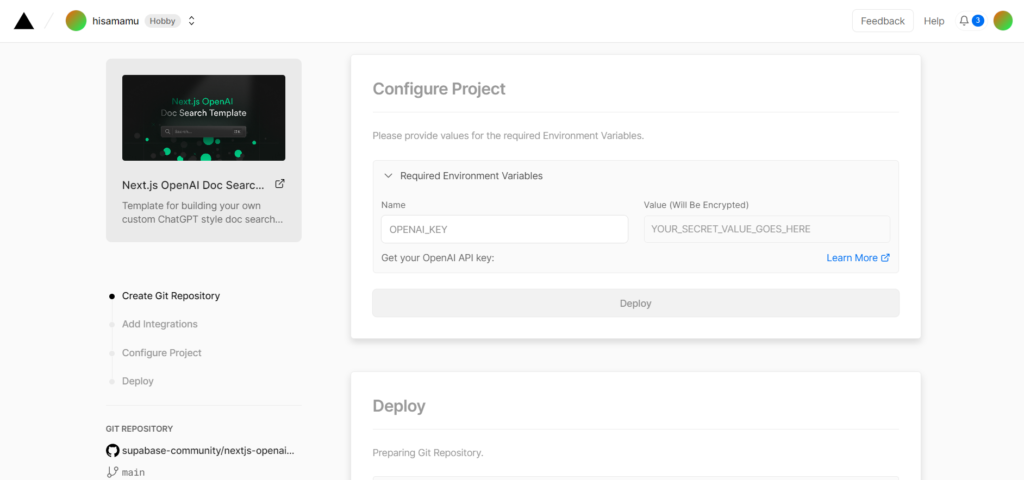
①「Next.js OpenAI Doc Search Starter」を使ってサイトを作る

②Vercelのウィザードで、OpenAI API keyを入力しデプロイする

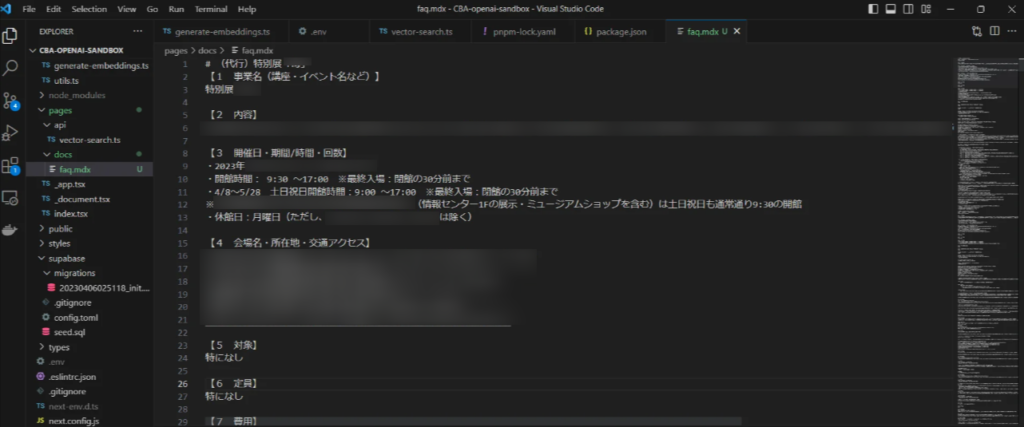
③エクセル形式のFAQ情報をマークダウン形式に変換する

④EmbeddingsAPIを使ってFAQ文章をベクトル化し、pgvectorに格納する

⑤動作確認をする

⑧デモ開発の振り返りをしてください

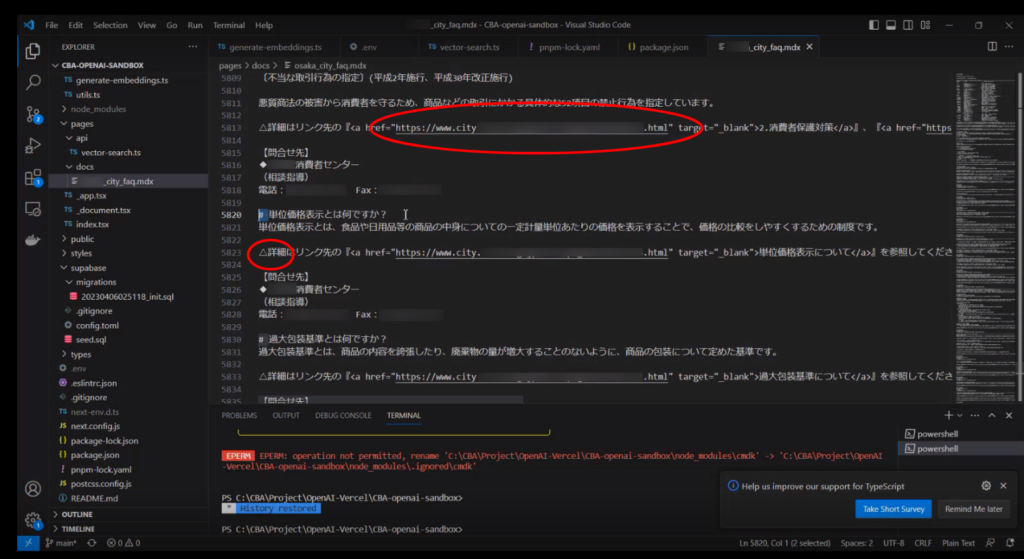
難しかった点:エクセル形式のFAQのテキストをベクトル化する際、上記の図のようなマークダウン形式へ変更する必要があります。
しかし、FAQの回答例に含まれる「ダブルクォーテーション」「記号」(図の赤丸箇所)などが引っ掛かり、マークダウン形式へスムーズに落とし込むのが難しいことがあります。
対応:マクロでFAQのエクセルファイルを指定し、出力というボタンを押すと、mdxへ出力されるプログラムを作りました。
気づいた点:「△」などの記号や「“”」で挟まれるURLが、OpenAIのAPIに嫌われて、ベクトル化できないことがありました。
さらに、自治体から提供していただくファイル形式は多岐にわたります。Word、Excel、PowerPoint、Webサイトなどです。さまざまな形式のテキスト情報をAPIが読みやすく成形する作業を効率化していきたいです。
自治体から提供されるテキスト情報をベクトル化するための「下準備」を、いかに効率化的に実施するかが今後のテーマです。
開発者が扱いやすいテキストデータとは:特殊文字を使っていないものです。またQ&A形式ですでに整理されているデータも扱いやすいです。
⑨自治体用のGPT開発において今後の課題は何ですか
ときに、自治体から提供されたひとつのPDF文書に、FAQをはじめ、ありとあらゆる情報が含められていることがあります。雑多な情報をどのように分割し、AIに読み込ませていくかが課題です。
ひとまずすべての情報をAIに読み込ませて、GPTに分割してもらう方法を考えています。GPTにFAQを作ってもらうイメージです。
ただGPT任せですと、大量のQ&Aが生成されます。FAQというのは質問が多ければ多いほど良いというわけではありません。そこで類似する質問をどの程度まで集約するか、それを人手でするのか、GPTにさせるか、それともハイブリッドでするのかなどを今後は突き詰めていきたいです。
⑩今後やってみたい開発はありますか
テキスト情報をベクトル化し、検索できる形式にする工程を効率化させたいです。
そのために「AWS Kendra」や「Azure Cognitive Search」を使った工程を作っていきたいと思っています。
【開発レポート】ChatGPTと電話で話せる?テキストだけじゃない活用法 - TPIJ by CBA |
編集後記
GPTによる回答生成は、意外と仕込みの部分がキモであることが分かりました。テキスト情報を何でもAIに読み込ませれば、勝手に情報を整理整頓し、回答を生成しているといったイメージがありましたが、実際はそうではなかったようです。
今回、開発者へのインタビューによって見えてきたのは、AIが「赤ちゃん」であるといったイメージです。それも成長がとてつもなく早い赤ちゃん。赤子なのでテキスト情報を自分では上手に食べられません。そのため、エンジニアが食べやすいように情報を調理し、AIに食べさせてあげるといった作業が必要になります。そして、AIはテキストを食べれば食べるほど、正しい言葉を発せられるよう急速に成長していきます。
ついAIが生成する回答の精度に驚きがちですが、その裏には開発者のテキスト情報を準備する細かな工程があるのだということが分かりました。「AWS Kendra」や「Azure Cognitive Search」を用いて、「調理」の効率化が進むことを願っています。
今回は、自治体用のChatGPTのデモ開発について解説しました。
TPIJブログでは、これからも顧客接点に関係するさまざまな開発の様子、新技術の実装についてのレポートを発信していきます。設定の内容やエンジニアが感じた開発中の気づきも含めてお伝えしていきます。
何か顧客接点において「こんなことを試してほしい」というご希望がございましたらTPIJ編集部へご相談ください。

